
 摘要:
...
摘要:
... 引言
AI行业近期的发展,被一部分人视为第四次工业革命,大模型的出现显著提升了各行各业的效率, 波士顿咨询认为GPT为美国提升了大约20%的工作效率。同时大模型带来的泛化能力被喻为新的软件设计范式,过去软件设计是***的代码,现在的软件设计是更泛化的大模型框架嵌入到软件中,这些软件能具备更好的表现和支持更广泛模态输入与输出。深度学习技术确实为AI行业带来了第四次繁荣,并且这一股风潮也弥漫到了Crypto行业。
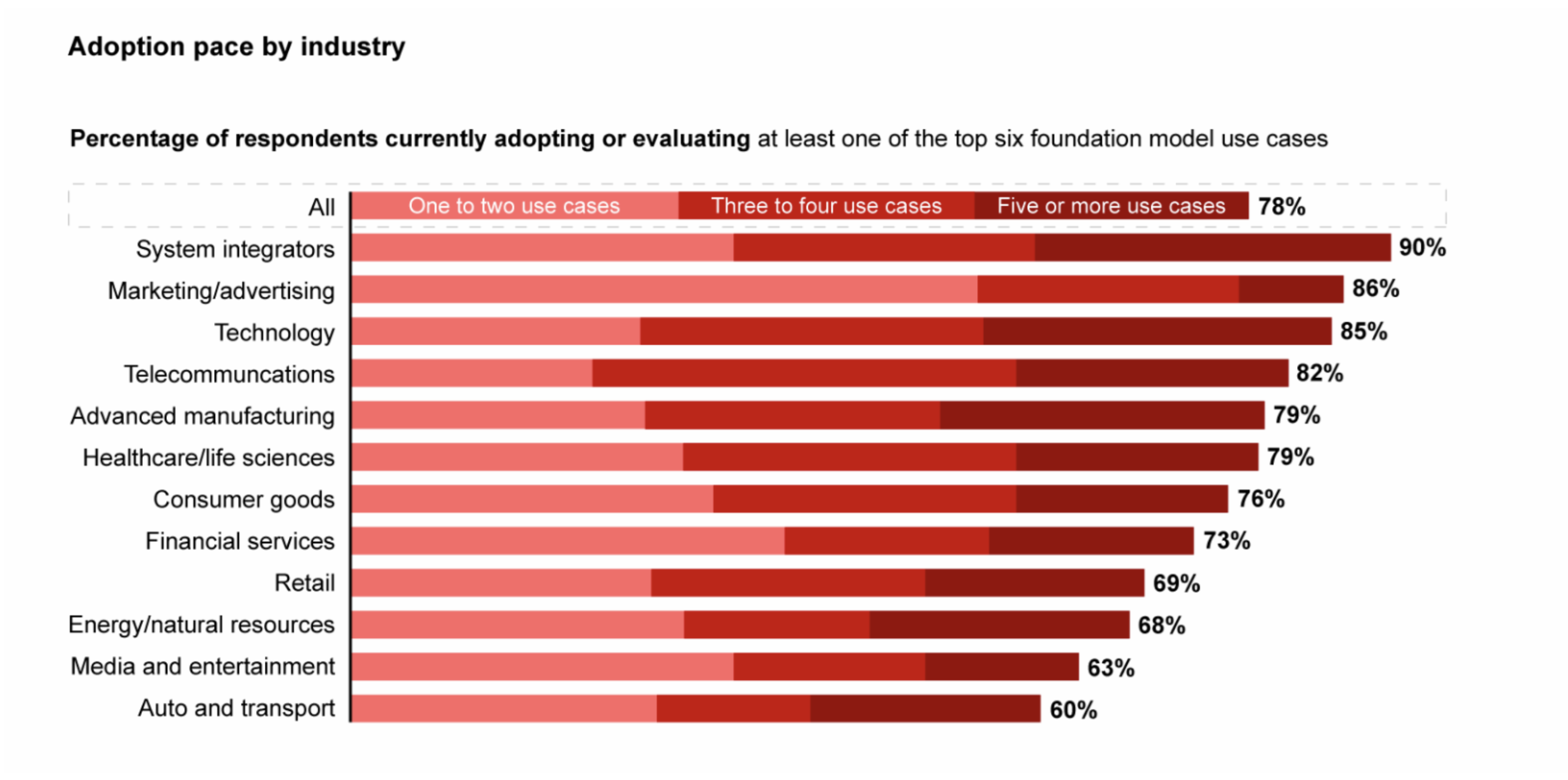
各行业GPT的采用率排名,Source:Bain AI Survey
在本报告中,我们将详细探讨AI行业的发展历史、技术分类、以及深度学习技术的发明对行业的影响。然后深度剖析深度学习中GPU、云计算、数据源、边缘设备等产业链上下游,以及其发展现状与趋势。之后我们从本质上详细探讨了Crypto与AI行业的关系,对于Crypto相关的AI产业链的格局进行了梳理。
AI行业的发展历史
AI行业从20世纪50年代起步,为了实现人工智能的愿景,学术界和工业界在不同时代不同学科背景的情况下,发展出了许多实现人工智能的流派。
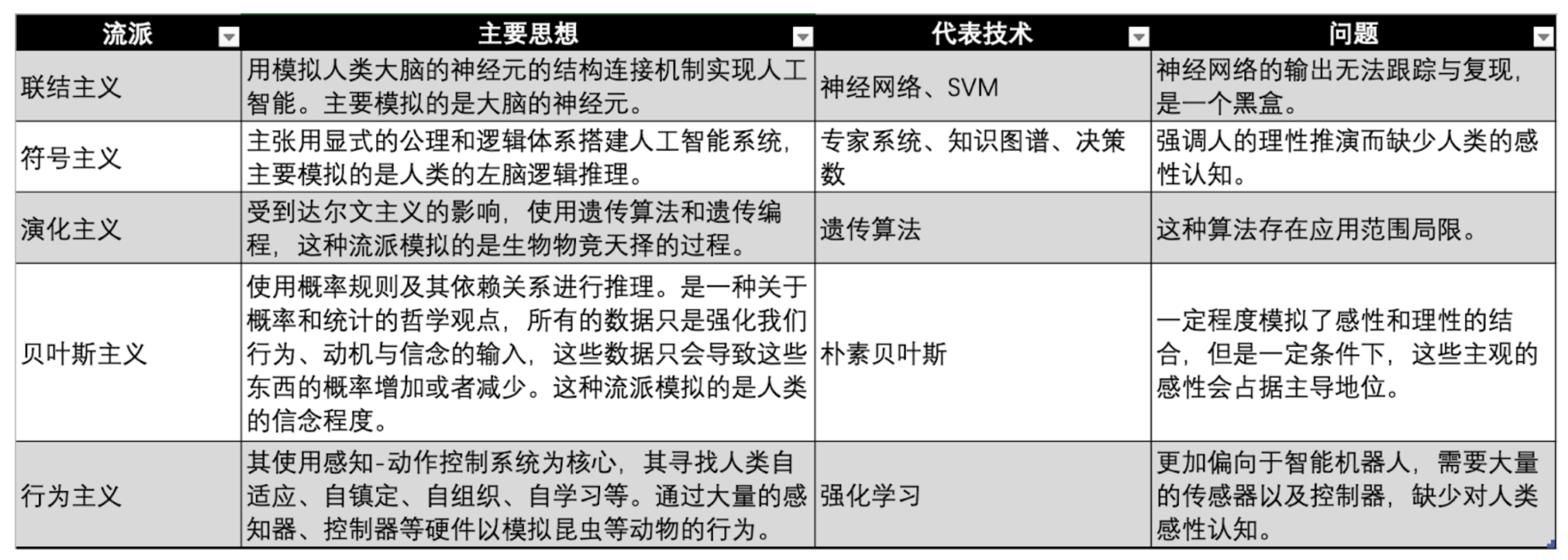
实现AI流派对比,图源:Gate Ventures
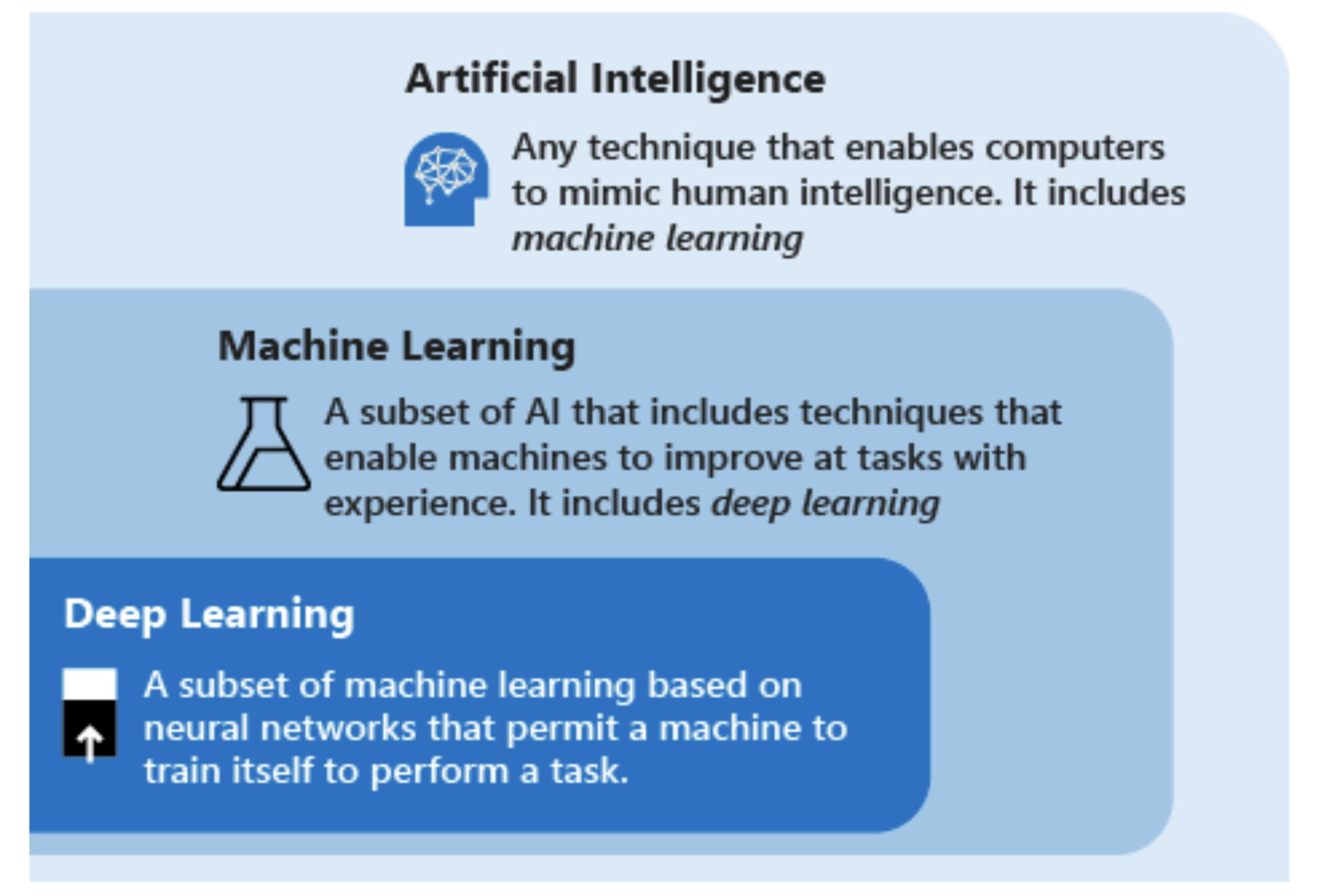
AI/ML/DL关系,图源:Microsoft
现代人工智能技术使用的主要是“机器学习”这一术语,该技术的理念是让机器依靠数据在任务中反复迭代以改善系统的性能。主要的步骤是将数据送到算法中,使用此数据训练模型,测试部署模型,使用模型以完成自动化的预测任务。
目前机器学习有三大主要的流派,分别是联结主义、符号主义和行为主义,分别模仿人类的神经系统、思维、行为。
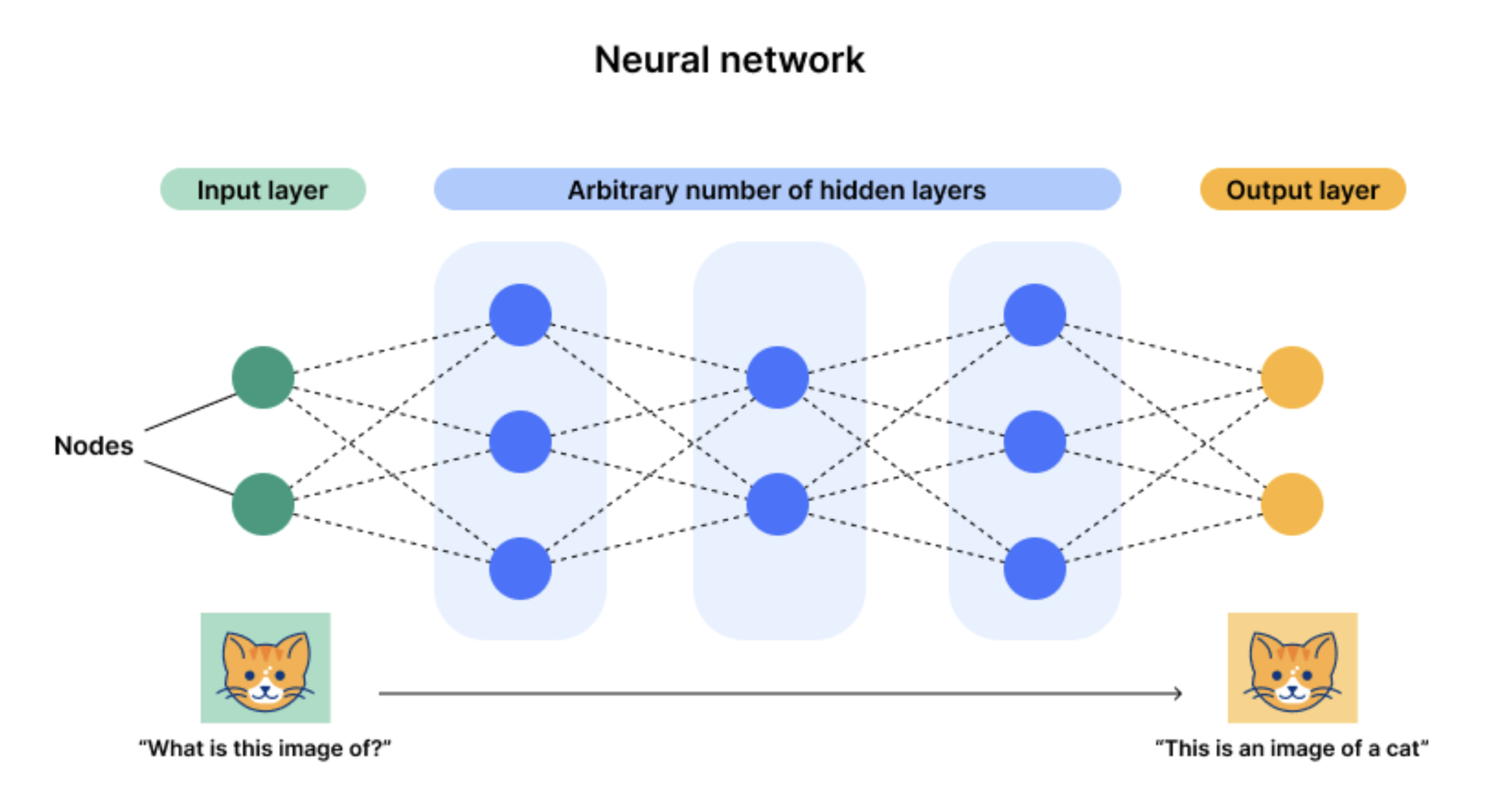
神经网络架构图示,图源:Cloudflare
而目前以神经网络为代表的联结主义占据上风(也被称为深度学习),主要原因是这种架构有一个输入层一个输出层,但是有多个隐藏层,一旦层数以及神经元(参数)的数量变得足够多,那么就有足够的机会拟合复杂的通用型任务。通过数据输入,可以一直调整神经元的参数,那么***后经历过多次数据,该神经元就会达到一个***佳的状态(参数),这也就是我们说的大力出奇迹,而这也是其“深度”两字的由来——足够多的层数和神经元。
举个例子,可以简单理解就是构造了一个函数,该函数我们输入X=2时,Y=3;X=3时,Y=5,如果想要这个函数应对所有的X,那么就需要一直添加这个函数的度及其参数,比如我此时可以构造满足这个条件的函数为Y = 2X -1 ,但是如果有一个数据为X=2,Y=11时,就需要重构一个适合这三个数据点的函数,使用GPU进行暴力破解发现Y = X2 -3X +5,比较合适,但是不需要完全和数据重合,只需要遵守平衡,大致相似的输出即可。这里面X2以及X、X0都是代表不同的神经元,而1、-3、5就是其参数。
此时如果我们输入大量的数据到神经网络中时,我们可以增加神经元、迭代参数来拟合新的数据。这样就能拟合所有的数据。
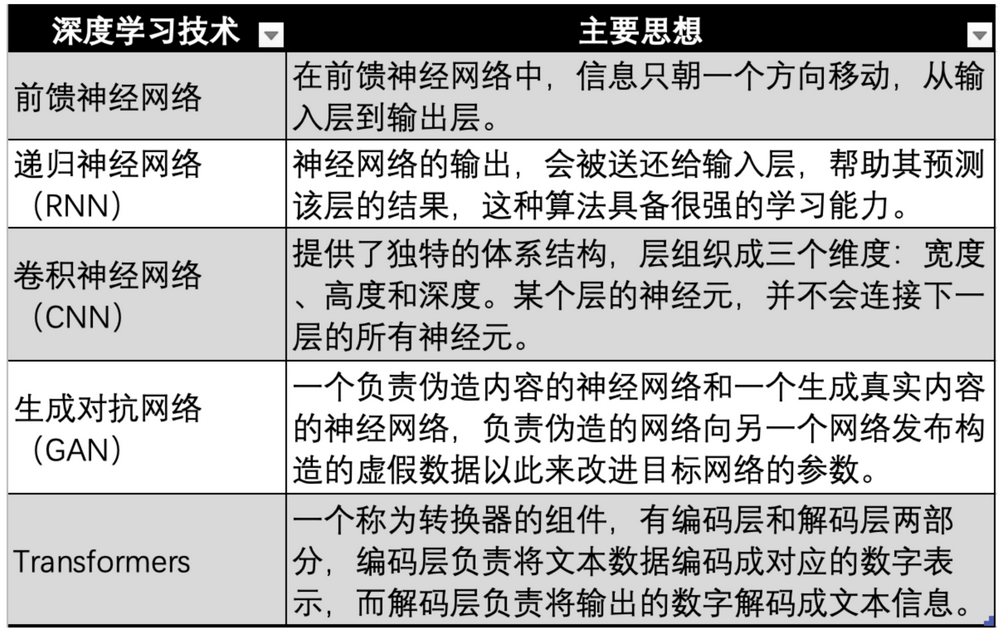
深度学习技术演进,图源:Gate Ventures
而基于神经网络的深度学习技术,也有多个技术迭代与演进,分别如上图的***早期的神经网络,前馈神经网络、RNN、CNN、GAN***后演进到现代大模型如GPT等使用的Transformer技术,Transformer技术只是神经网络的一个演进方向,多加了一个转换器(Transformer),用于把所有模态(如音频,视频,图片等)的数据编码成对应的数值来表示。然后再输入到神经网络中,这样神经网络就能拟合任何类型的数据,也就是实现多模态。
AI发展经历了三次技术浪潮,***次浪潮是20世纪60年代,是AI技术提出的十年后,这次浪潮是符号主义技术发展引起的,该技术解决了通用的自然语言处理以及人机对话的问题。同时期,专家系统诞生,这个是斯坦福大学在美国***航天局的督促下完成的DENRAL专家系统,该系统具备非常强的化学知识,通过问题进行推断以生成和化学专家一样的答案,这个化学专家系统可以被视为化学知识库以及推断系统的结合。
在专家系统之后,20世纪90年代以色列裔的美国科学家和哲学家朱迪亚·珀尔(Judea Pearl)提出了贝叶斯网络,该网络也被称为信念网络。同时期,Brooks提出了基于行为的机器人学,标志着行为主义的诞生。
1997年,IBM深蓝“Blue”以3.5:2.5战胜了国际象棋***卡斯帕罗夫(Kasparov),这场胜利被传视为人工智能的一个里程碑,AI技术迎来了第二次发展的高潮。
第三次AI技术浪潮发生在2006年。深度学习三巨头Yann LeCun 、Geoffrey Hinton 以及Yoshua Bengio提出了深度学习的概念,一种以人工神经网络为架构,对资料进行表征学习的算法。之后深度学习的算法逐渐演进,从RNN、GAN到Transformer以及Stable Diffusion,这两个算法共同塑造了这第三次技术浪潮,而这也是联结主义的鼎盛时期。
许多标志性的事件也伴随着深度学习技术的探索与演进逐渐涌现,包括:
-
2011年,IBM 的沃森(Watson)在《危险边缘》(Jeopardy)回答测验节目中战胜人类、获得***。
-
2014年,Goodfellow提出GAN(生成式对抗网络,Generative Adversarial Network),通过让两个神经网络相互博弈的方式进行学习,能够生成以假乱真的照片。同时Goodfellow还写了一本书籍《Deep Learning》,称为花书,是深度学习领域重要入门书籍之一。
-
2015年,Hinton等人在《自然》杂志提出深度学习算法,该深度学习方法的提出,立即在学术圈以及工业界引起巨大反响。
-
2015年,OpenAI创建,Musk、YC总裁Altman、天使投资人彼得·泰尔(Peter Thiel)等人宣布共同注资10亿美元。
-
2016年,基于深度学习技术的AlphaGo与围棋世界***、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜。
-
2017年,中国香港的汉森机器人技术公司(Hanson Robotics)开发的类人机器人索菲亚,其称为历史上***获得一等公民身份的机器人,具备丰富的面部表情以及人类语言理解能力。
-
2017年,在人工智能领域有丰富人才、技术储备的Google发布论文《Attention is all you need》提出Transformer算法,大规模语言模型开始出现。
-
2018年,OpenAI 发布了基于Transformer算法构建的GPT(Generative Pre-trained Transformer),这是当时***大的语言模型之一。
-
2018年,Google团队Deepmind发布基于深度学习的AlphaGo,能够进行蛋白质的结构预测,被视为人工智能领域的巨大进步性标志。
-
2019年,OpenAI发布GPT-2,该模型具备15亿个参数。
-
2020年,OpenAI开发的GPT-3,具有1,750亿个参数,比以前的版本GPT-2高100倍,该模型使用了570GB的文本来训练,可以在多个NLP(自然语言处理)任务(答题、翻译、写文章)上达到***先进的性能。
-
2021年,OpenAI发布GPT-4,该模型具备1.76万亿个参数,是GPT-3的10倍。
-
2023年1月基于GPT-4模型的ChatGPT应用程序推出,3月ChatGPT达到一亿用户,成为历史***快达到一亿用户的应用程序。
-
2024年,OpenAI推出GPT-4 omni。
注:由于人工智能的论文很多、流派很多、技术演变不一,因此在这里主要是跟随深度学习或者联结主义的发展历史,其它流派和技术仍然处于高速发展的过程中。
深度学习产业链
当前大模型语言使用的都是基于神经网络的深度学习方法。以GPT为首的大模型造就了一波人工智能的热潮,大量的玩家涌入这个赛道,我们也发现市场对于数据、算力的需求大量迸发,因此在报告的这一部分,我们主要是探索深度学习算法的产业链,在深度学习算法主导的AI行业,其上下游是如何组成的,而上下游的现状与供需关系、未来发展又是如何。

GPT训练Pipeline 图源:WaytoAI
首先我们需要明晰的是,在进行基于Transformer技术的GPT为首的LLMs(大模型)训练时,一共分为三个步骤。
在训练之前,因为是基于Transformer,因此转换器需要将文本输入转化为数值,这个过程被称为“Tokenization”,之后这些数值被称为Token。在一般的经验法则下,一个英文单词或者字符可以粗略视作一个Token,而每个汉字可以被粗略视为两个Token。这个也是GPT计价使用的基本单位。
***步,预训练。通过给输入层足够多的数据对,类似于报告***部分所举例的(X,Y),来寻找该模型下各个神经元***佳的参数,这个时侯需要大量的数据,而这个过程也是***耗费算力的过程,因为要反复迭代神经元尝试各种参数。一批数据对训练完成之后,一般会使用同一批数据进行二次训练以迭代参数。
第二步,微调。微调是给予一批量较少,但是质量非常高的数据,来训练,这样的改变就会让模型的输出有更高的质量,因为预训练需要大量数据,但是很多数据可能存在错误或者低质量。微调步骤能够通过优质数据提升模型的品质。
第三步,强化学习。首先会建立一个全新的模型,我们称其为“奖励模型”,这个模型目的非常简单,就是对输出的结果进行排序,因此实现这个模型会比较简单,因为业务场景比较垂直。之后用这个模型来判定我们大模型的输出是否是高质量的,这样就可以用一个奖励模型来自动迭代大模型的参数。(但是有时候也需要人为参与来评判模型的输出质量)
简而言之,在大模型的训练过程中,预训练对数据的量有非常高的要求,所需要耗费的GPU算力也是***多的,而微调需要更加高质量的数据来改进参数,强化学习可以通过一个奖励模型来反复迭代参数以输出更高质量的结果。
在训练的过程中,参数越多那么其泛化能力的天花板就越高,比如我们以函数举例的例子里,Y = aX + b,那么实际上有两个神经元 X以及X0,因此参数如何变化,其能够拟合的数据都极其有限,因为其本质仍然是一条直线。如果神经元越多,那么就能迭代更多的参数,那么就能拟合更多的数据,这就是为什么大模型大力出奇迹的原因,并且这也是为什么通俗取名大模型的原因,本质就是巨量的神经元以及参数、巨量的数据,同时需要巨量的算力。
因此,影响大模型表现主要由三个方面决定,参数数量、数据量与质量、算力,这三个共同影响了大模型的结果质量和泛化能力。我们假设参数数量为p,数据量为n(以Token数量进行计算),那么我们能够通过一般的经验法则计算所需的计算量,这样就可以预估我们需要大致购买的算力情况以及训练时间。
算力一般以Flops为基本单位,代表了一次浮点运算,浮点运算是非整数的数值加减乘除的统称,如2.5+3.557,浮点代表着能够带小数点,而FP16代表了支持小数的精度,FP32是一般更为常见的精度。根据实践下的经验法则,预训练(Pre-traning)一次(一般会训练多次)大模型,大概需要 6np Flops,6被称为行业常数。而推理(Inference,就是我们输入一个数据,等待大模型的输出的过程),分成两部分,输入n个token,输出n个token,那么大约一共需要2np Flops。
在早期,使用的是CPU芯片进行训练提供算力支持,但是之后开始逐渐使用GPU替代,如Nvidia的A100、H100芯片等。因为CPU是作为通用计算存在的,但是GPU可以作为专用的计算,在能耗效率上远远超过CPU。GPU运行浮点运算主要是通过一个叫Tensor Core的模块进行。因此一般的芯片有FP16 / FP32精度下的Flops数据,这个代表了其主要的计算能力,也是芯片的主要衡量指标之一。
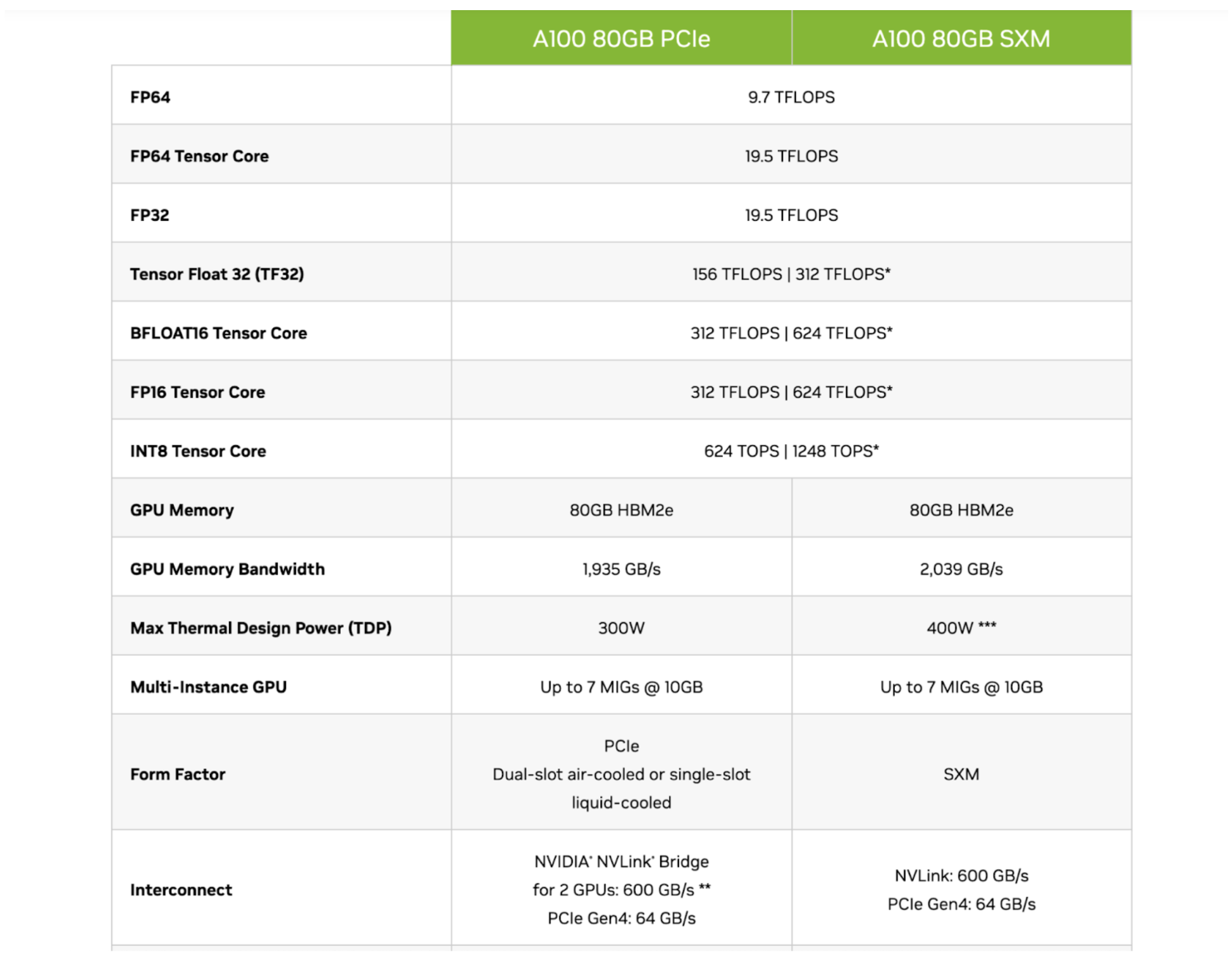
Nvidia A100芯片的Specification,Source:Nvidia
因此读者应该能够看懂这些企业的芯片介绍,如上图所示,Nvidia的A100 80GB PCIe和SXM型号的对比中,看出PCIe和SXM在Tensor Core(专门用于计算AI的模块)下,在FP16精度下,分别是312TFLOPS和624TFLOPS(Trillion Flops)。
假设我们的大模型参数以GPT3为例,有1750亿个参数,1800亿个Token的数据量(大约为570GB),那么在进行一次预训练时,就需要6np的Flops,大约为3.15*1022 Flops,如果以TFLOPS(Trillion FLOPs)为单位大约为3.15*1010 TFLOPS,也就是说一张SXM型号的芯片预训练一次GPT3大约需要 50480769秒,841346分钟,14022小时,584天。
我们能够看到这个及其庞大的计算量,需要多张***先进的芯片共同计算才能够实现一次预训练,并且GPT4的参数量又是GPT3的十倍(1.76 trillion),意味着即使数据量不变的情况下,芯片的数量要多购买十倍,并且GPT-4的Token数量为13万亿个,又是GPT-3的十倍,***终,GPT-4可能需要超过100倍的芯片算力。
在大模型训练中,我们的数据存储也有问题,因为我们的数据如GPT3 Token数量为1800亿个,大约在存储空间中占据570GB,大模型1750亿个参数的神经网络,大约占据700GB的存储空间。GPU的内存空间一般都较小(如上图介绍的A100为80GB),因此在内存空间无法容纳这些数据时,就需要考察芯片的带宽,也就是从硬盘到内存的数据的传输速度。同时由于我们不会只使用一张芯片,那么就需要使用联合学习的方法,在多个GPU芯片共同训练一个大模型,就涉及到GPU在芯片之间传输的速率。所以在很多时候,制约***后模型训练实践的因素或者成本,不一定是芯片的计算能力,更多时侯可能是芯片的带宽。因为数据传输很慢,会导致运行模型的时间拉长,电力成本就会提高。

H100 SXM芯片Specification,Source:Nvidia
这个时侯,读者大致就能完全看懂芯片的Specification了,其中FP16代表精度,由于训练AI LLMs主要使用的是Tensor Core组件,因此只需要看这个组件下的计算能力。FP64 Tensor Core代表了在64精度下每秒H100 SXM能够处理67 TFLOPS。GPU memory意味着芯片的内存仅有64GB,完全无法满足大模型的数据存储要求,因此GPU memory bandwith就意味着数据传输的速度,H100 SXM为3.35TB/s。
AI Value Chain,图源:Nasdaq
我们看到了,数据、神经元参数数量的膨胀带来的大量算力以及存储需求的缺口。这三个主要的要素孵化了一整条的产业链。我们将根据上图来介绍产业链中每一个部分在其中扮演的角色以及作用。
硬件GPU提供商
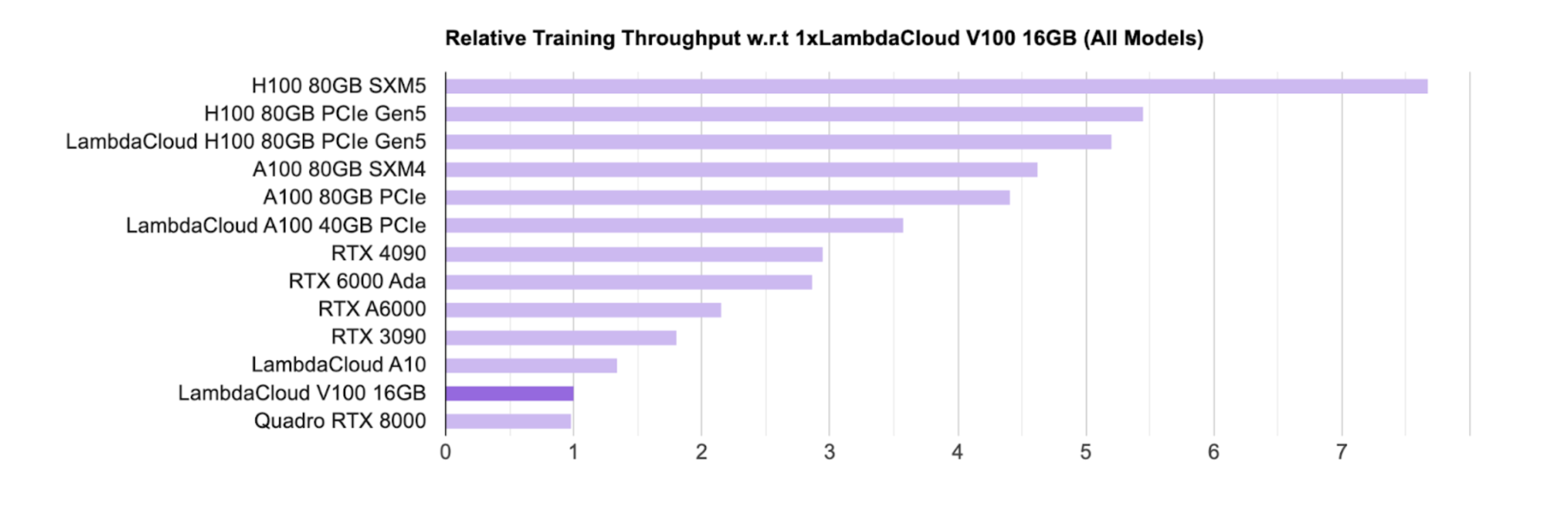
AI GPU芯片Rankings,Source:Lambda
硬件如GPU是目前进行训练和推理的主要芯片,对于GPU芯片的主要设计商方面,目前Nvidia处于***的领先地位,学术界(主要是高校和研究机构)主要是使用消费级别的GPU(RTX,主要的游戏GPU);工业界主要是使用H100、 A100等用于大模型的商业化落地。
在榜单中,Nvidia的芯片几乎屠榜,所有芯片都来自Nvidia。Google也有自己的AI芯片被称为TPU,但是TPU主要是Google Cloud在使用,为B端企业提供算力支持,自购的企业一般仍然倾向于购买Nvidia的GPU。
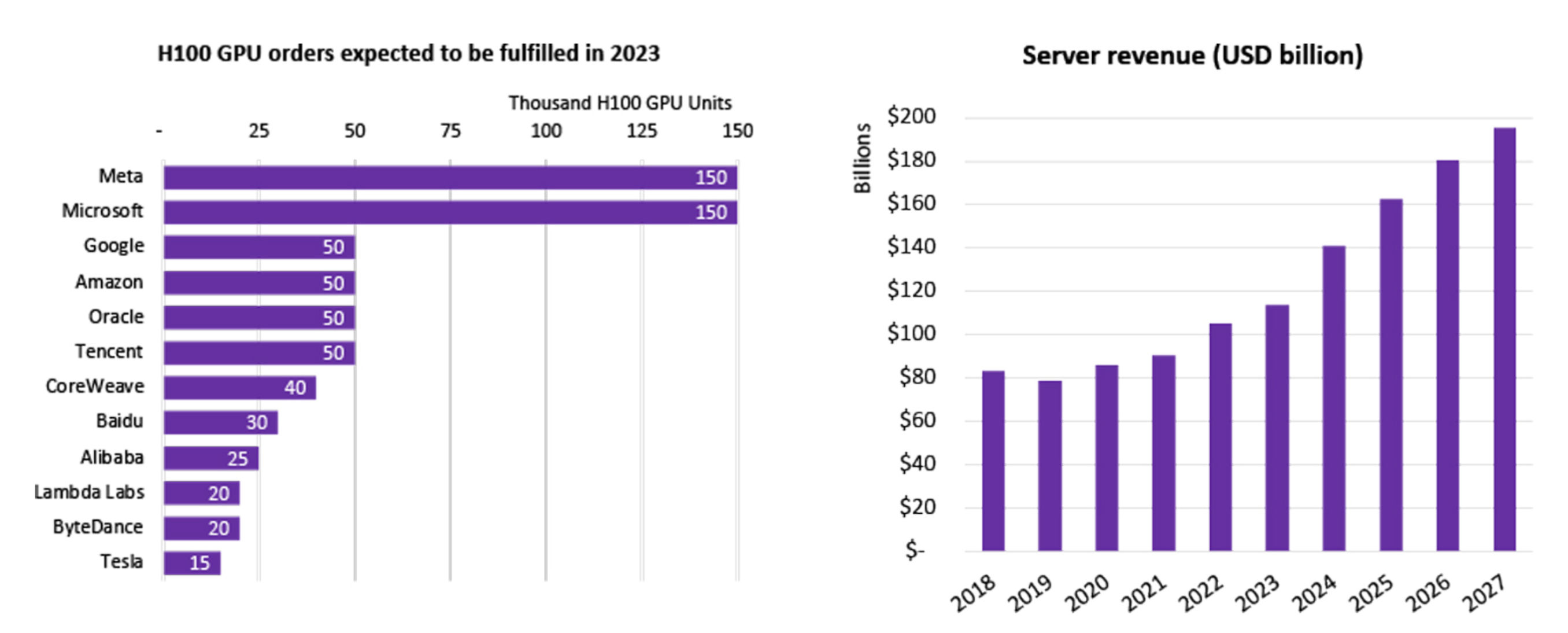
H100 GPU Purchase Statistics by Company,Source:Omdia
大量的企业着手进行LLMs的研发,包括中国就有超过一百个大模型,而全球一共发行了超过200个大语言模型,许多互联网巨头都在参与这次AI热潮。这些企业要么是自购大模型、要么是通过云企业进行租赁。2023年,Nvidia***先进的芯片H100一经发布,就获得了多家公司的认购。全球对H100芯片的需求远远大于供给,因为目前仅仅只有Nvidia一家在供给***高端的芯片,其出货周期已经达到了惊人的52周之久。
鉴于Nvidia的垄断情况,Google作为人工智能的***领头企业之一,谷歌牵头,英特尔、高通、微软、亚马逊共同成立了CUDA联盟,希望共同研发GPU以摆脱 Nvidia对深度学习产业链的***影响力。
对于 超大型科技公司/云服务提供商/***实验室来说,他们动则购买上千、上万片H100芯片,用以组建HPC(高性能计算中心),比如Tesla的CoreWeave集群购买了一万片H100 80GB,平均购买价为44000美元(Nvidia 成本大约为1/10),总共花费4.4亿美元;而Tencent更是购买5万片;Meta狂买15万片,截***2023年底,Nvidia作为***高性能GPU卖家,H100芯片的订购量就超过了50万片。
參考來源
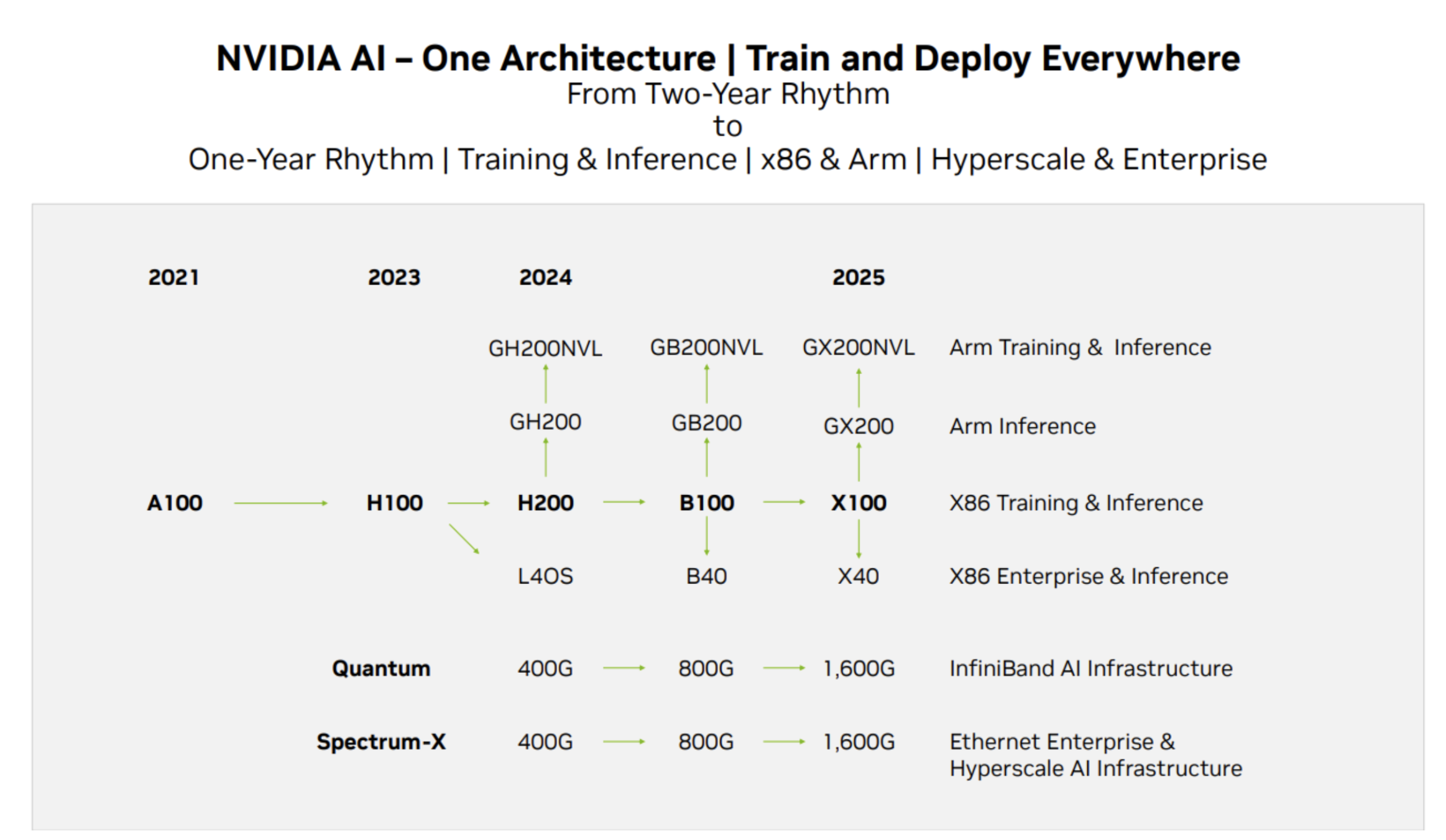
Nvidia GPU产品路线图,Source:Techwire
在Nvidia的芯片供给方面,以上是其产品迭代路线图,目前截***该报告,H200的消息已经发出,预计H200的性能是H100性能的两倍,而B100将在2024年底或者2025年初推出。目前GPU的发展仍然满足摩尔定律,性能每2年翻一倍,价格下降一半。
云服务提供商

Types of GPU Cloud, Source: Salesforce Ventures
云服务提供商在购买足够的GPU组建HPC后,能够为资金有限的人工智能企业提供弹性的算力以及托管训练解决方案。如上图所示,目前市场主要分为三类云算力提供商,***类是以传统云厂商为代表的超大规模拓展的云算力平台(AWS、Google、Azure)。第二类是垂直赛道的云算力平台,主要是为AI或者高性能计算而布置的,他们提供了更专业的服务,因此在与巨头竞争中,仍然存在一定的市场空间,这类新兴垂直产业云服务企业包括CoreWeave(C轮获得11以美元融资,估值190亿美元)、Crusoe、Lambda(C轮融资2.6亿美元,估值超过15亿美元)等。第三类云服务提供商是新出现的市场玩家,主要是推理即服务提供商,这些服务商从云服务商租用GPU,这类服务商主要为客户部署已经预训练完毕的模型,在之上进行微调或者推理,这类市场的代表企业包括了Together.ai(***新估值12.5亿美元)、Fireworks.ai(Benchmark领投,A轮融资2500万美元)等。
训练数据源提供商
正如我们第二部分前面所述,大模型训练主要经历三个步骤,分别为预训练、微调、强化学习。预训练需要大量的数据,微调需要高质量的数据,因此对于Google这种搜索引擎(拥有大量数据)和Reddit(优质的对答数据)这种类型的数据公司就受到市场的广泛关注。
有些开发厂商为了不与GPT等通用型的大模型竞争,选择在细分领域进行开发,因此对数据的要求就变成了这些数据是特定行业的,比如金融、医疗、化学、物理、生物、图像识别等。这些是针对特定领域的模型,需要特定领域的数据,因此就存在为这些大模型提供数据的公司,我们也可以叫他们Data labling company,也就是为采集数据后为数据打标签,提供更加优质与特定的数据类型。
对于模型研发的企业来说,大量数据、优质数据、特定数据是三种主要的数据诉求。
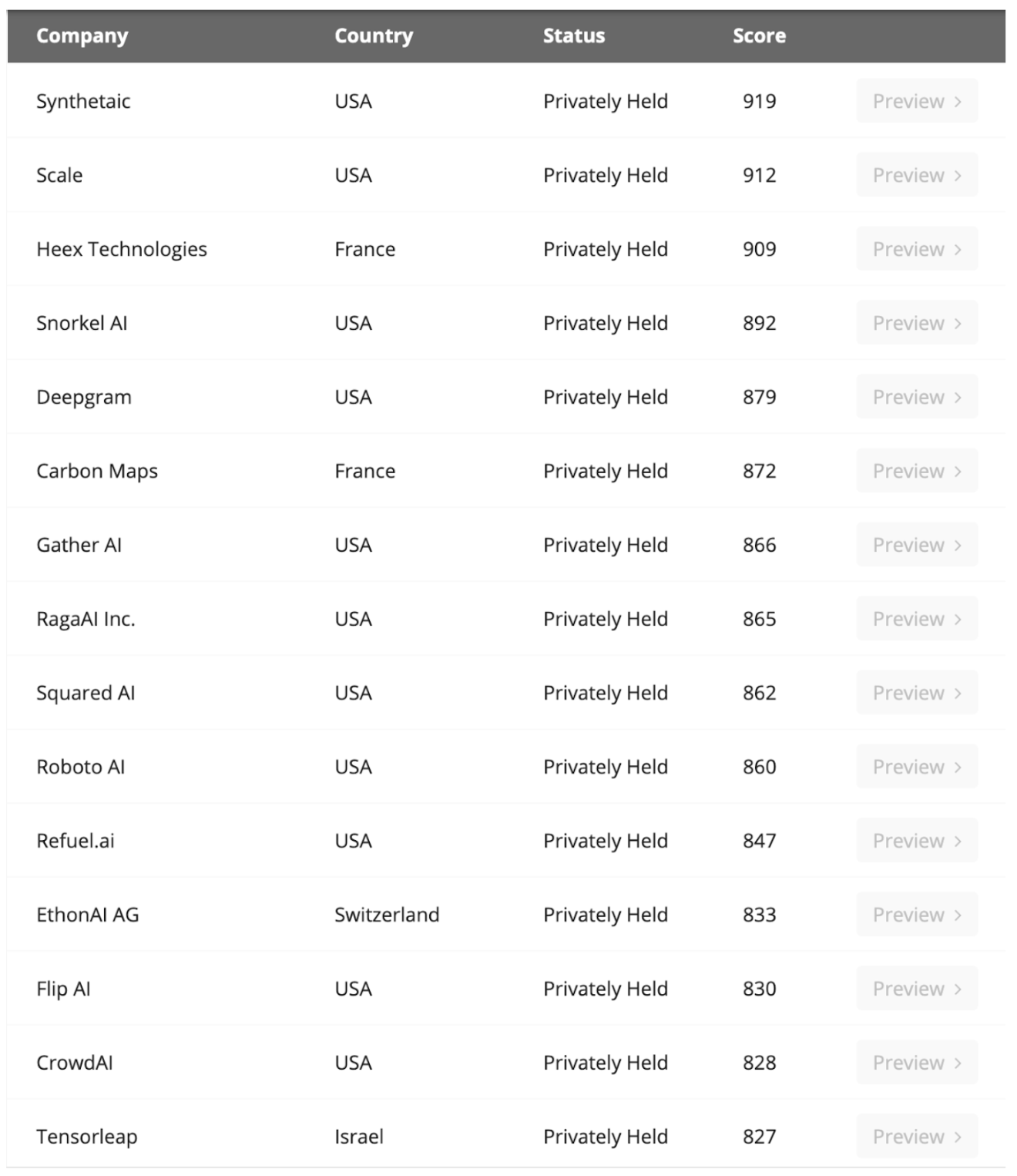
主要Data Labeling公司,Source:Venture Radar
微软的一项研究认为对于SLM(小语言模型)来说,如果他们的数据质量明显优于大语言模型,那么其性能不一定会比LLMs差。并且实际上GPT在原创力以及数据上并没有明显的优势,主要是其对该方向的押注的胆量造就了其成功。红杉美国也坦言,GPT在未来不一定会保持竞争优势,原因是目前这方面没有太深的护城河,主要的限制来源于算力获取的限制。
对于数据量来说,根据EpochAI的预测,按照当前的模型规模增长情况,2030年所有的低质量和高质量数据都会耗尽。所以目前业内正在探索人工智能合成数据,这样就可以生成无限的数据,那么瓶颈就只剩下算力,这个方向仍然处于探索阶段,值得***们关注。
数据库提供商
我们有了数据,但是数据也需要存储起来,一般是存放在数据库中,这样方便数据的增删改查。在传统的互联网业务中,我们可能听说过MySQL,在以太坊客户端Reth中,我们听说过Redis。这些都是我们存放业务数据或者区块链 链上数据的本地数据库。对于不同的数据类型或者业务有不同的数据库适配。
对于AI数据以及深度学习训练推理任务,目前业内使用的数据库称为“矢量数据库”。矢量数据库旨在高效地存储、管理和索引海量高维矢量数据。因为我们的数据并不是单纯的数值或者文字,而是图片、声音等海量的非结构化的数据,矢量数据库能够将这些非结构化的数据统一以“向量”的形式存储,而矢量数据库适合这些向量的存储和处理。

Vector Database Classification , Source: Yingjun Wu
目前主要的玩家有Chroma(获得1800万美元融资轮融资)、Zilliz(***新一轮融资6000万美元)、Pinecone、Weaviate等。我们预计伴随着数据量的需求增加,以及各种细分领域的大模型和应用的迸发,对Vector Database的需求将大幅增加。并且由于这一领域有很强的技术壁垒,在投资时更多考虑偏向于成熟和有客户的企业。
边缘设备
在组建GPU HPC(高性能计算集群)时,通常会消耗大量的能量,这就会产生大量的热能,芯片在高温环境下,会限制运行速度以降低温度,这就是我们俗称的“降频”,这就需要一些降温的边缘设备来保证HPC持续运行。
所以这里涉及到产业链的两个方向,分别是能源供应(一般是采用电能)、冷却系统。
目前在能源供给侧,主要是采用电能,数据中心及支持网络目前占全球电力消耗的2%-3%。BCG预计随着深度学习大模型参数的增长以及芯片的迭代,截***2030年,训练大模型的电力将增长三倍。目前国内外科技厂商正在积极投资能源企业这一赛道,投资的主要能源方向包括地热能、氢能、电池存储和核能等。
在HPC集群散热方面,目前是以风冷为主,但是许多VC正在大力投资液冷系统,以维持HPC的平稳运行。比如Jetcool就声称其液冷系统能够为H100集群的总功耗降低15%。目前液冷主要分成三个探索方向分别为冷版式液冷、浸没式液冷、喷淋式液冷。这方面的企业有:华为、Green Revolution Cooling 、SGI等。
应用
当前AI应用的发展,类似于区块链行业的发展,作为一个创新性的行业,Transformer是在2017年提出,OpenAI是在2023年才证实大模型的有效性。所以现在许多Fomo的企业都拥挤在大模型的研发赛道,也就是基础设施非常拥挤,但是应用开发却没有跟上。
參考來源

Top 50月活用户,Source:A16Z
目前前十月活的AI应用大多数是搜索类型的应用,实际走出来的AI应用还非常有限,应用类型较为单一,并没有一些社交等类型的应用成功闯出来。
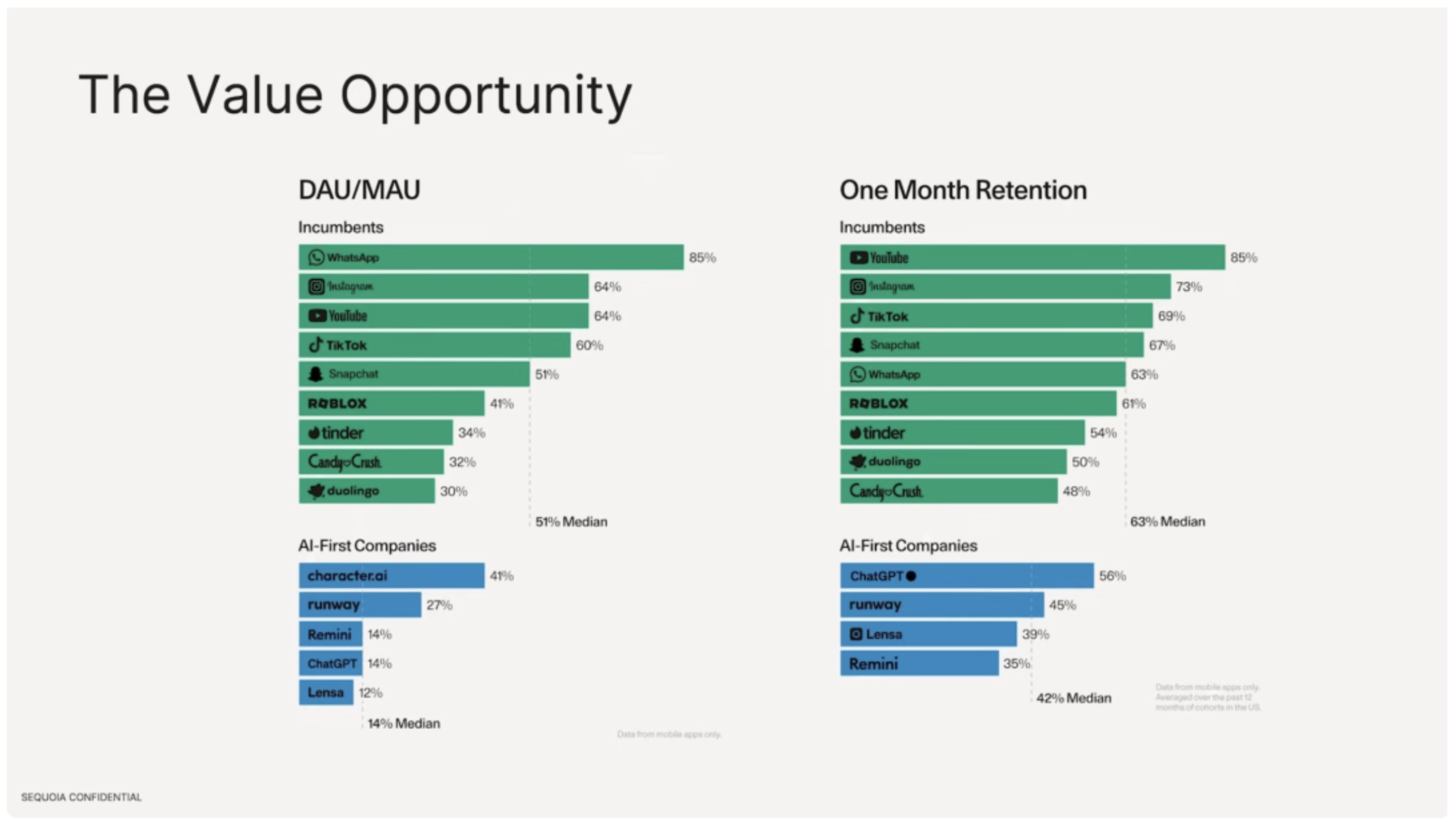
我们同时发现,基于大模型的AI应用,其留存率远低于现有的传统互联网应用。活跃用户数方面,传统的互联网软件中位数在51%,***高的是Whatsapp,具备很强的用户粘性。但是在AI应用侧,DAU/MAU***高的为character.ai仅仅为41%,DAU占据总用户数量的中位数14%。在用户留存率方面,传统互联网软件***好的是Youtube、Instagram、Tiktok,前十的留存率中位数为63%,相比之下ChatGPT留存率仅仅为56%。

AI Application Landscape, Source: Sequoia
根据红杉美国的报告,其将应用从面向的角色角度分为三类,分别是面向专业消费者、企业、普通消费者。
-
面向消费者:一般用于提升生产力,如文字工作者使用GPT进行问答,自动化的3D渲染建模,软件剪辑,自动化的代理人,使用Voice类型的应用进行语音对话、陪伴、语言练习等。
-
面向企业:通常是Marketing、法律、医疗设计等行业。
虽然现在有很多人批评,基础设施远大于应用,但其实我们认为现代世界已经广泛的被人工智能技术所重塑,只不过使用的是推荐系统,包括字节跳动旗下的tiktok、今日头条、汽水音乐等,以及小红书和微信视频号、广告推荐技术等都是为个人进行定制化的推荐,这些都属于机器学习算法。所以目前蓬勃发展的深度学习不完全代表AI行业,有许多潜在的有机会实现通用人工智能的技术也在并行发展,并且其中一些技术已经被广泛的应用于各行各业。
Crypto x AI的关系
区块链得益于ZK技术的发展,演变成了去中心化 + 去信任化的思想。我们回到区块链创造之初,是比特币链。在中本聪的论文《比特币,点对点的电子现金系统》中,其首先称其为去信任化的、价值转移系统。之后Vitalik等人发表了论文《A Next-Generation Smart Contract and Decentralized Application Platform》推出了去中心化、去信任化、价值互换的智能合约平台。
回到本质,我们认为整个区块链网络就是一个价值网络,每一笔交易都是以底层代币为基础的价值转换。这里的价值是Token的形式体现,而Tokenomics就是具体的Token价值体现的规则。
在传统的互联网中,价值的产生是以P/E进行结算,是有一个***终的形式体现,也就是股价,所有的流量、价值、影响力都会形成企业的现金流,这种现金流是价值的***后体现,***后折算成P/E反映到股价和市值上。
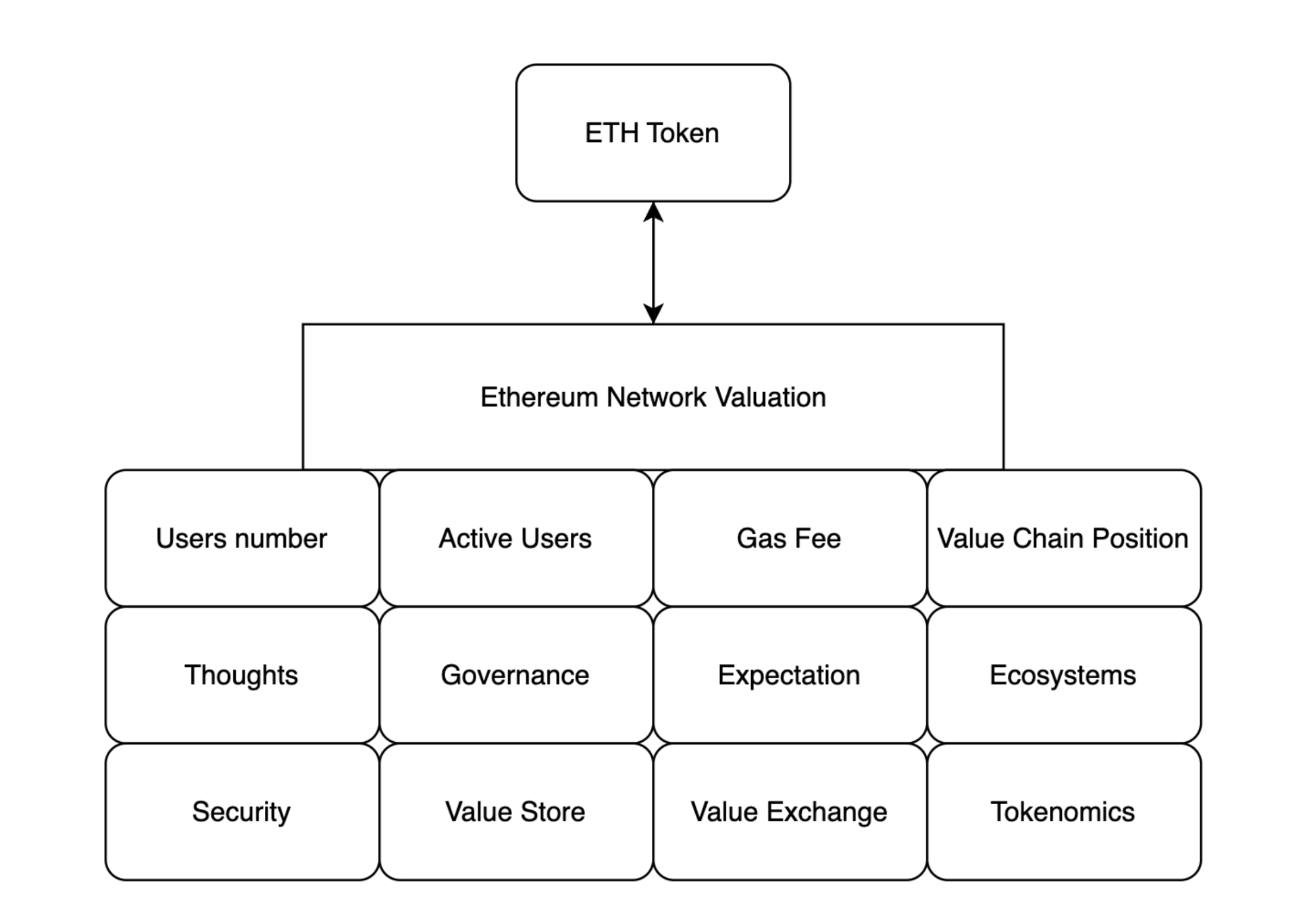
网络价值由原生代币价格以及多维度视角共同决定,Source: Gate Ventures
但是对于以太坊网络来说,ETH作为以太坊网络多种维度价值的的体现,其不仅仅能够通过质押获得稳定的现金流,还能充当价值交换的媒介、价值存储的媒介、网络活动的消费品等。并且,其还充当安全保护层Restaking、Layer2生态系统的Gas Fee等。
Tokenomics非常重要,代币经济学能够规定生态系统的结算物(也就是网络的原生代币)的相对价值,虽然我们无法为每一个维度进行定价,但是我们有了多维度价值的体现,这就是代币的价格。这种价值是远远超越企业的证券存在形式的。一旦为网络赋予代币,并且将该种代币进行流通,类似于腾讯的所有Q币有了限定的数量、通缩通膨的机制、代表了庞大腾讯的生态系统,作为结算物的存在、也能成为价值存储与生息的手段。这种价值肯定是远远超过股价的价值。而代币是多价值维度的***终体现。
代币很迷人,代币能够把一个功能或者某个思想赋予价值,我们使用浏览器,但是不会考虑到底层的开源HTTP协议的定价,如果发行了代币,那么其价值就会在交易中体现。一个MEME币的存在以及背后代表的诙谐思想也有价值,代币经济学能够为任何一种创新与存在赋予动力,无所谓是思想还是实物创造,代币经济学将世间的一切都价值化了。
代币和区块链技术这种对价值重新定义与发现的手段,对任何行业也***关重要,包括AI行业。在AI行业中,发行代币能够让AI产业链中的各方面都进行价值的重塑,那么会激励更多人愿意在AI行业各个细分赛道深根,因为其带来的收益将变得更为显著,不仅仅是现金流来决定其当前价值,并且代币的协同作用会让基础设施的价值得到提升,这会天然的导致胖协议瘦应用范式的形成。
其次,AI产业链中所有项目都将获得资本增值的收益,并且这种代币能够反哺生态系统以及促进某种哲学思想的诞生。
代币经济学显然对行业的影响是有其积极的一面,区块链技术的不可篡改和无需信任的性质也有其AI行业的实际意义,能够实现一些需要信任的应用,比如我们的用户数据能够允许在某个模型之上,但是确保模型不知道具体的数据、确保模型不泄露数据、确保返回该模型推理的真实数据。当GPU不足够时,能够通过区块链网络分销,当GPU迭代,闲置的GPU能贡献算力到网络中,重新发现剩余价值,这是全球化的价值网络才能做到的事情。
总之,代币经济学能够促进价值的重塑和发现,去中心化账本能够解决信任问题,将价值在全球范围重新流动起来。
Crypto行业Value Chain项目概览
GPU供给侧
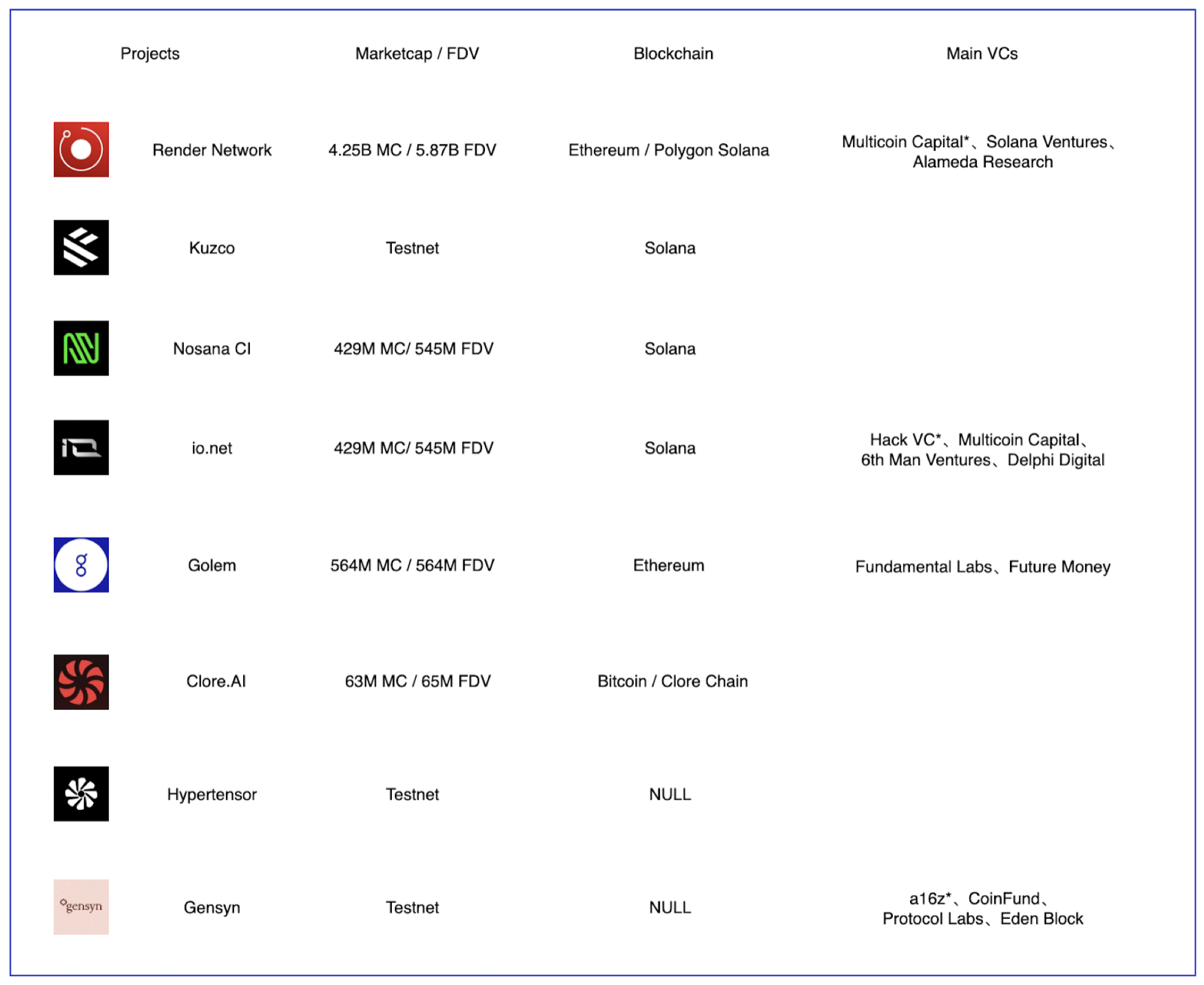
GPU云算力市场部分项目,Source:Gate Ventures
以上是GPU云算力市场的主要项目参与者,市值与基本面发展较好的是Render,其在2020年推出,但是由于数据不公开与透明,因此我们暂时无法得知其业务实时发展状况。目前使用Render进行业务的绝大多数是非大模型类的视频渲染任务。
Render作为有实际业务量的老牌Depin业务,确实乘着AI / Depin的风成功了,但是Render面向的场景与AI并不同,因此严格意义上不算是AI板块。并且其视频渲染业务确实有一定的真实需求,因此GPU云算力市场不仅仅可以面向AI模型的训练、推理,也可以应用于传统渲染任务,这降低了GPU云市场依赖单一市场风险。
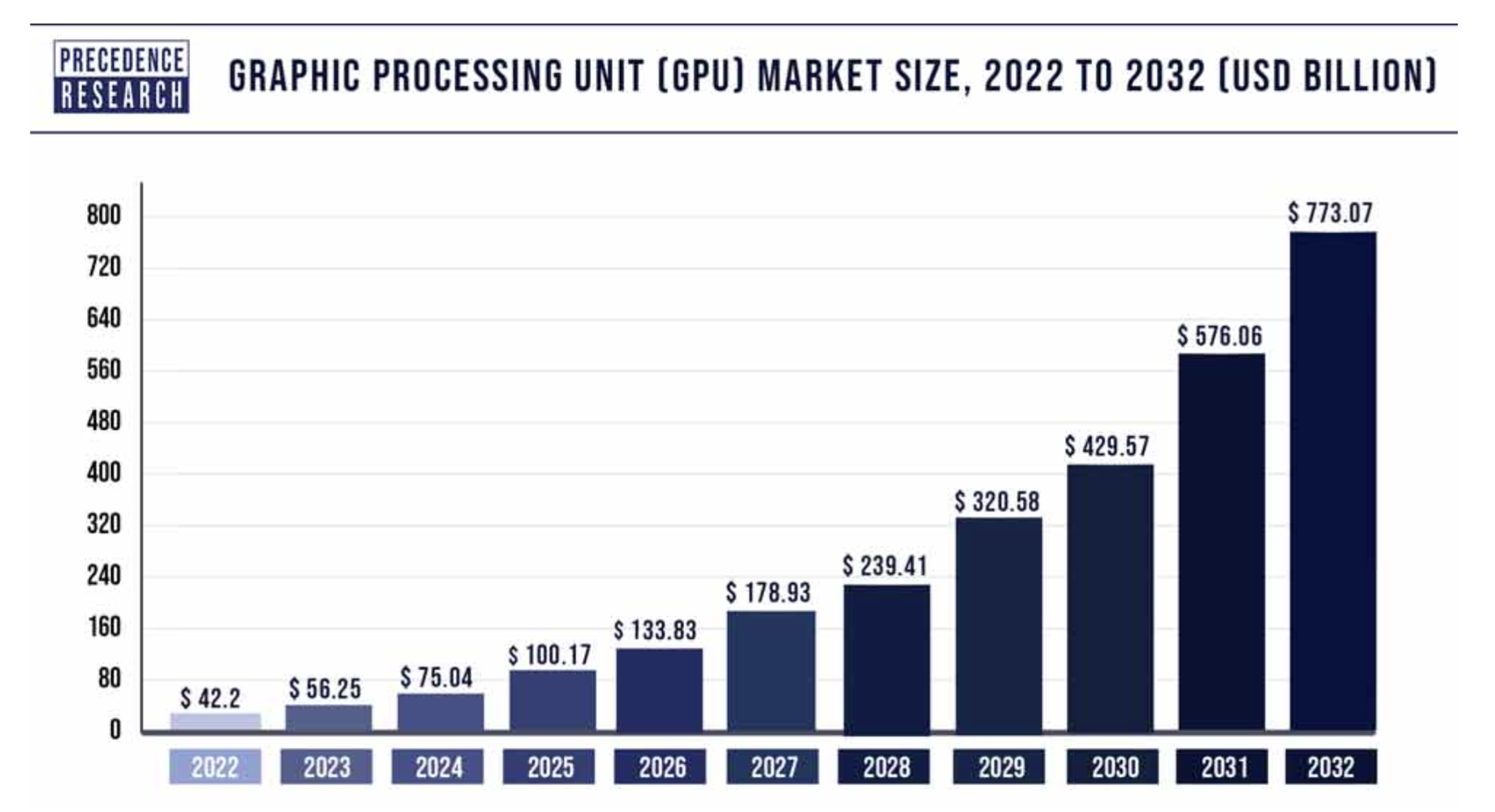
全球GPU算力需求趋势,Source:PRECEDENCE RESEARCH
在Crypto关于AI的产业链中,算力供给无疑是***重要的一点。根据行业预测,2024年GPU的算力需求大约有750亿美元,到2032年大约有7730亿美元的市场需求,年化复合增长率(CAGR)约为33.86%。
GPU的迭代率遵循摩尔定律(18-24各月性能翻倍,价格下降一半),那么对于共享GPU算力的需求将会变得极大,因为GPU市场的爆发,会在未来摩尔定律的影响下,形成大量的非***新几代的GPU,这时侯这些闲置的GPU将作为长尾算力在共享网络中继续发挥其价值,因此我们确实看好这个赛道的长期潜力和实际效用,不仅仅是中小模型的业务还有传统的渲染业务也会形成比较强的需求。
值得提醒的是,注意到许多报告都将低廉的价格作为这些产品的主要产品卖点,以此来说明链上GPU共享以及计算市场的广阔空间,但是我们想要强调的是,决定云算力市场的定价不仅仅是使用的GPU有关,还和数据传输的带宽、边缘设备、配套的AI托管***工具等有关。但是在带宽、边缘设备等相同的情况下,由于存在代币补贴,一部分价值是由代币和网络效应共同决定的,确实有更低廉的价格,这是价格上的优势,但是同时也有其网络数据传输缓慢导致模型研发、渲染任务缓慢的缺点。
硬件带宽
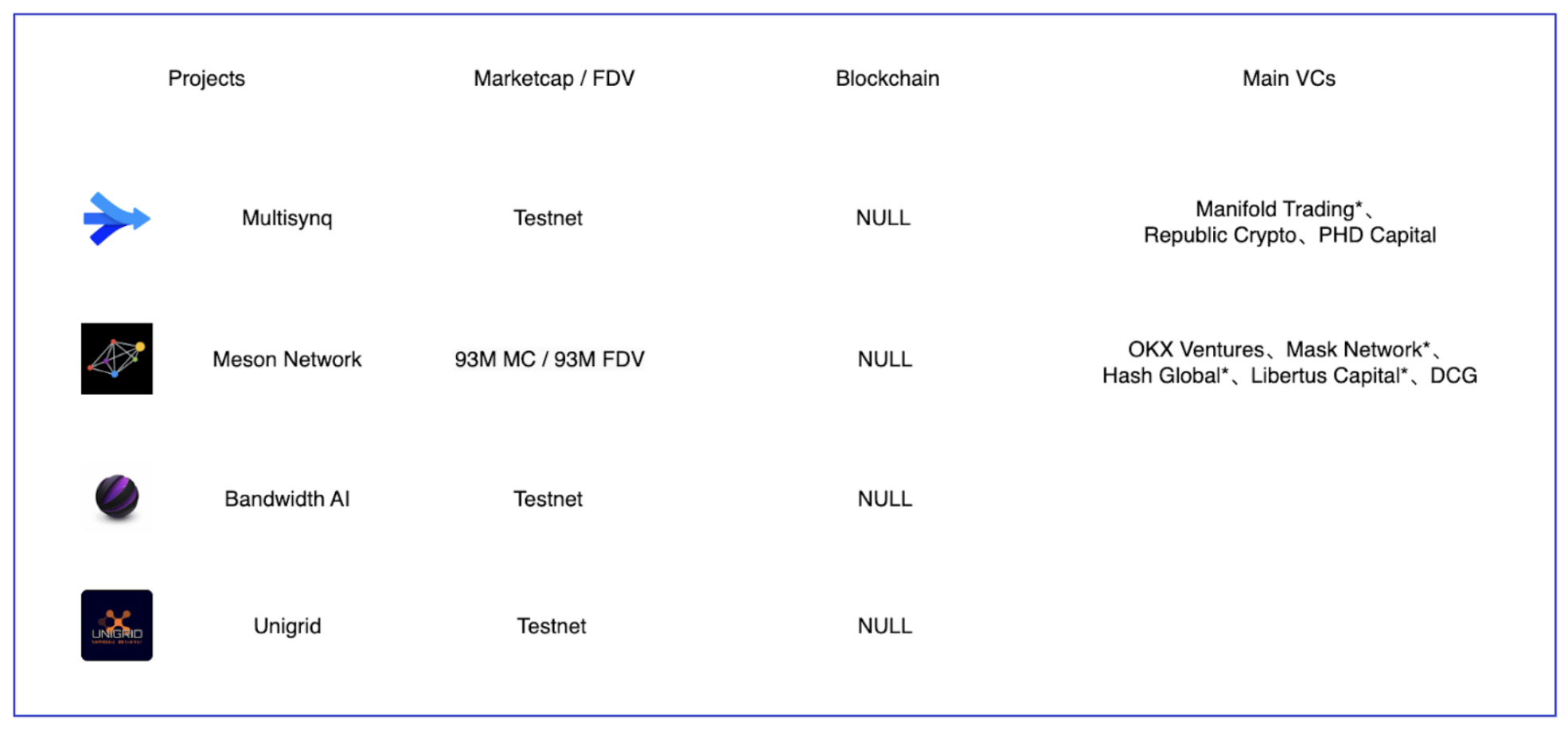
共享带宽赛道部分项目,Source:Gate Ventures
就像我们在 GPU供给侧所述,云算力厂商的定价往往与GPU芯片有关,但是还与带宽、冷却系统、AI配套开发工具等有关。在报告的AI产业链章节处,我们也提到由于大模型的参数和数据容量的问题,在传递数据过程中会显著影响大模型训练的时间,因此很多时候带宽才是影响大模型的主要原因,特别对于链上云计算领域,其带宽以及数据交换更慢,影响更大,因为是各地的用户进行的协同工作,但是在其它的云厂商如azure等都是建立集中化的HPC,更便于协调和改善带宽。
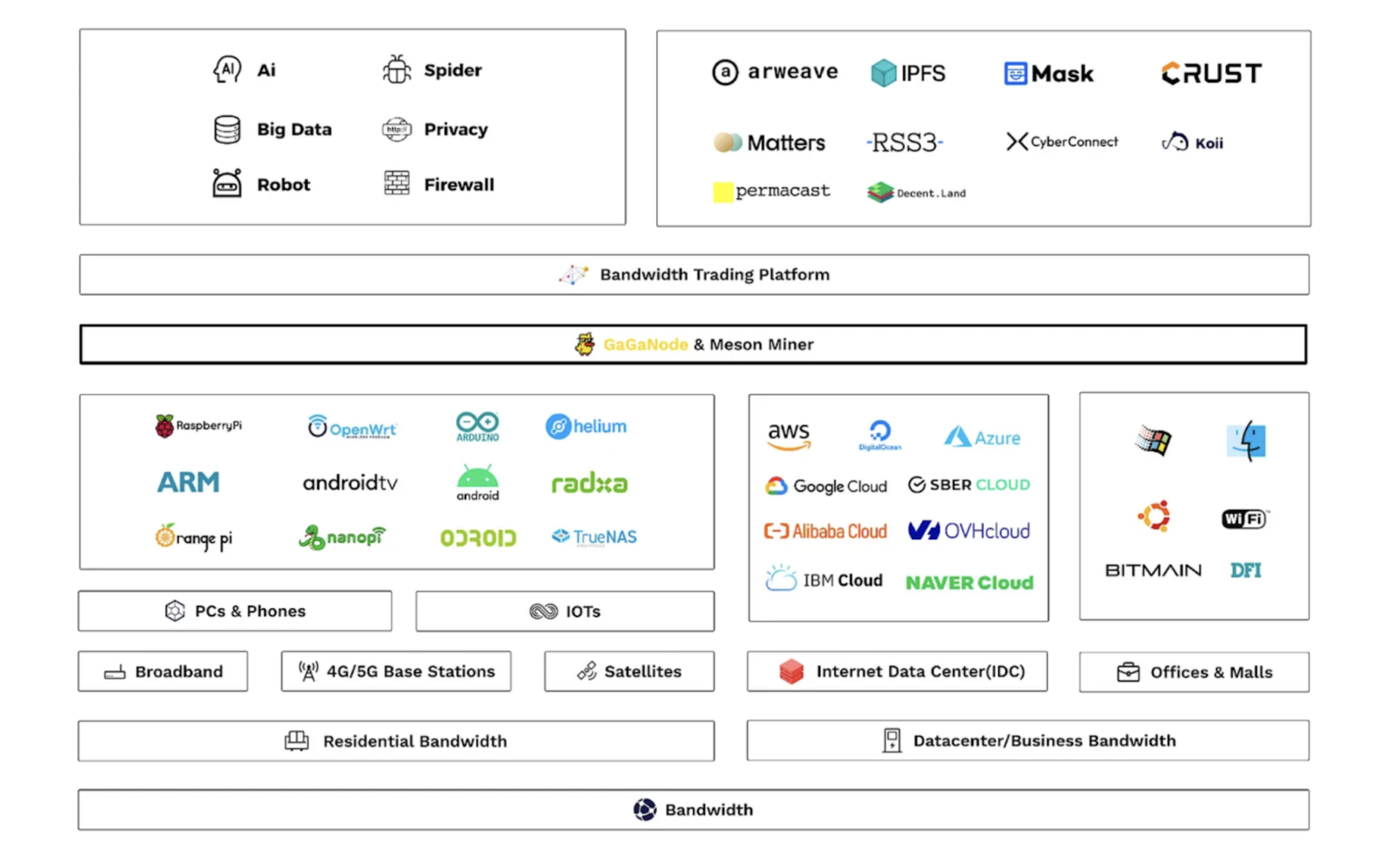
Menson Network架构图,图源:Meson
以Menson Network为例,其Meson 设想的未来是,用户可以轻松地将剩余带宽换成代币,而有需要的人可以在 Meson 市场内访问全球带宽。用户可以将数据存放在用户的数据库中,而其它用户就可以访问***近的用户存储的数据,以此加速网络数据的交换,加快模型的训练速度。
但是我们认为,共享带宽是一个伪概念,因为对于HPC来说,其数据主要存储在本地节点,但是对于这种共享带宽,数据存储在有一定距离的(如1km、10km、100km)以外,这些地理位置的距离导致的延迟都会远远高于在本地进行数据存储,因为这样会导致频繁的调度分配。因此,这个伪需求也是市场不买账的原因,Meson Network ***新一轮融资估值10亿美元,上线交易所以后,FDV仅仅930万美元,不及估值的1/10。
数据
根据我们在深度学习产业链中所述,大模型的参数数量、算力、数据三方面共同影响着大模型的质量,这里有许多的数据源企业以及矢量数据库提供商的市场机会,他们会为企业提供各种特定类型的数据服务。
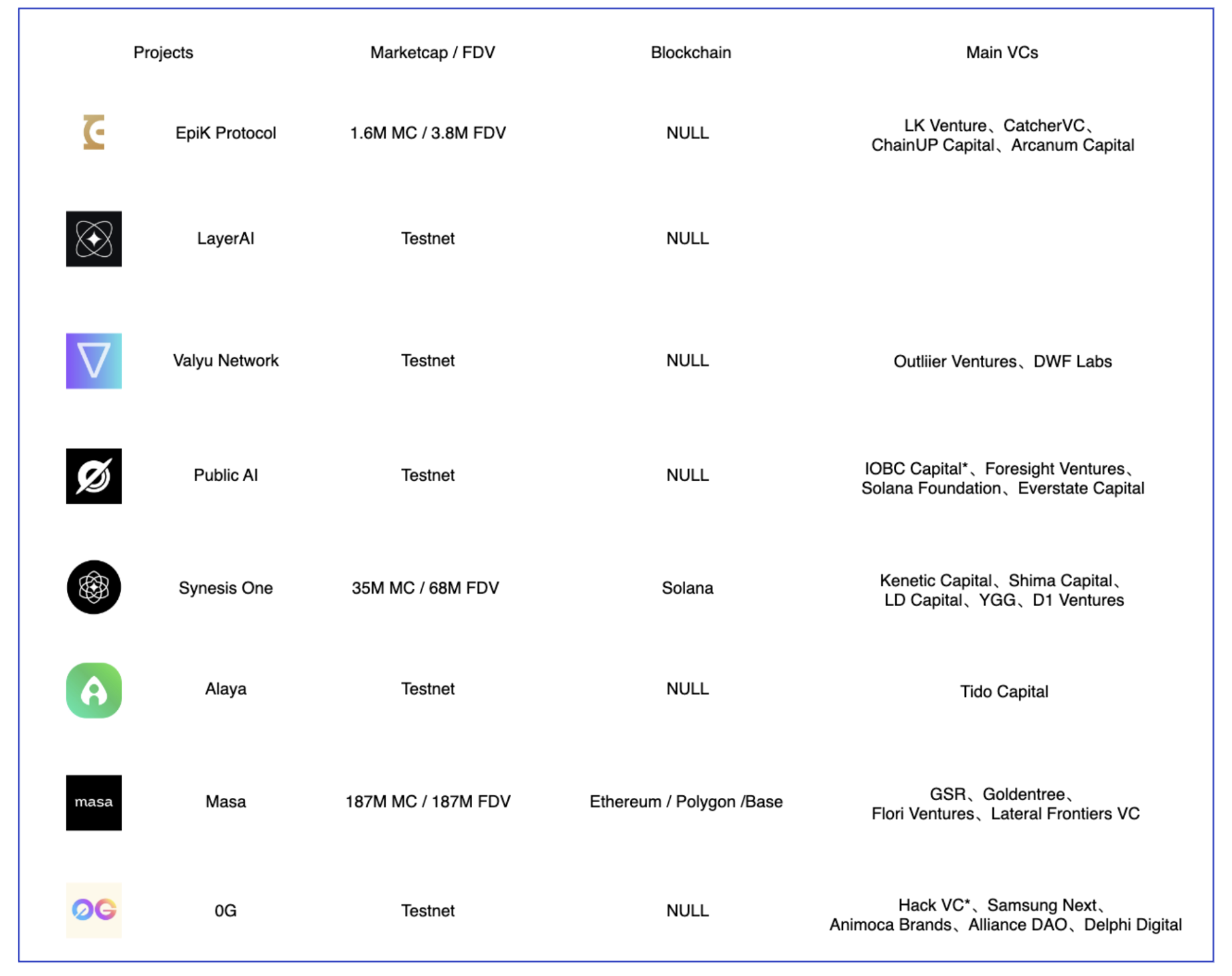
AI数据提供商部分项目,Source:Gate Ventures
目前上线的项目包括EpiK Protocol、Synesis One、Masa等,不同点在于EpiK protocol和Synesis One是对于公开数据源进行收集,但是Masa是基于ZK技术,能够实现隐私数据的收集,这样对于用户更加友好。
相比于其它Web2的传统数据企业,Web3数据提供商具备的优势在于数据采集侧,因为个人能够贡献自己非隐私的数据(ZK技术能促进用户贡献隐私数据但是不会显示泄漏),这样项目的接触面会变得很广,不仅仅是ToB,而且能够为任何用户的数据都进行定价,任何过去的数据都有了价值,并且由于代币经济学的存在,本身网络价值和价格是相互依赖的,0成本的代币随着网络价值变高也会变高,而这些代币会降低开发商的成本,用来奖励用户,用户贡献数据的动机将变得更足。
我们认为这种能够同时接触Web2以及Web3,并且在用户层面几乎任何人都有机会贡献自己数据的机制非常容易实现部分范围的“Mass Adoption”,在数据消费端是各种模型,有了真实的供需双方,并且用户在网上随意点击即可,操作难度也很低。***需要考虑的是隐私计算的问题,因此ZK方向的数据提供商可能有一个较好的发展前景,其中典型的项目包括Masa。
ZKML
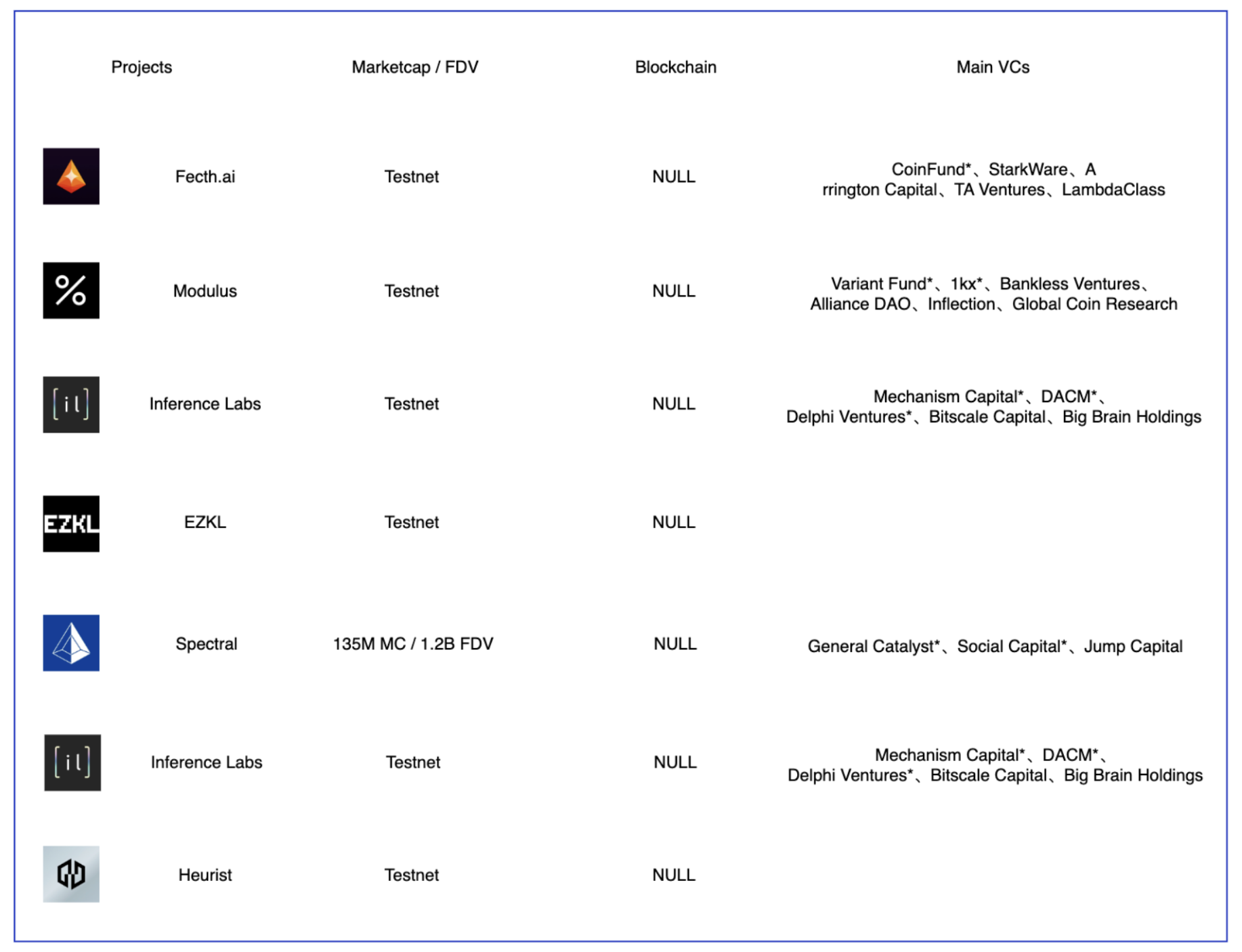
ZK Training / Inference Projects, Source: Gate Ventures
如果数据想要实现隐私计算以及训练,目前业内主要采用的ZK方案,使用同态加密技术,将数据在链下推理然后将结果和ZK证明上传,那么就能保证数据的隐私性和推理的低成本高效率。在链上是非常不适合推理的。这也是为什么ZKML赛道的投资者普遍质量更高的原因,因为这个才是符合商业逻辑的。
不仅仅这些专注于人工智能领域的链下训练和推理的项目存在,也有一些通用型的ZK项目,能够提供图灵完备的ZK协作处理能力,为任何链下计算和数据提供ZK证明,包括Axiom、Risc Zero、Ritual等项目也值得关注,这类型的项目应用边界更广,对于VC有更多的容错性。
AI 应用

AI x Crypto应用landscape,图源:Foresight News
区块链的应用情况也与传统的AI行业较为相似,大部分处于基础设施的建设,目前发展***为繁荣的仍然是上游产业链,但是下游产业链如应用端,发展的较为薄弱。
这类型的AI+区块链应用,更多是传统区块链应用 + 自动化和泛化能力。比如DeFi能够通过用户的想法来执行***优的交易、Lending路径,这类型的应用被称为AI Agent。神经网络和深度学习技术对软件革命***根本性在于其泛化能力,能够适配多种不同人群的不同需求,以及不同模态的数据。
而我们认为这种泛化能力,首先将使得AI Agent收益,其作为用户与多种应用的桥梁,能够帮助用户进行复杂的链上决策,选择***优路径。Fetch.AI就是其中代表性的项目(目前MC 21亿美元),我们以Fetch.AI来简述AI Agent工作原理。
參考來源
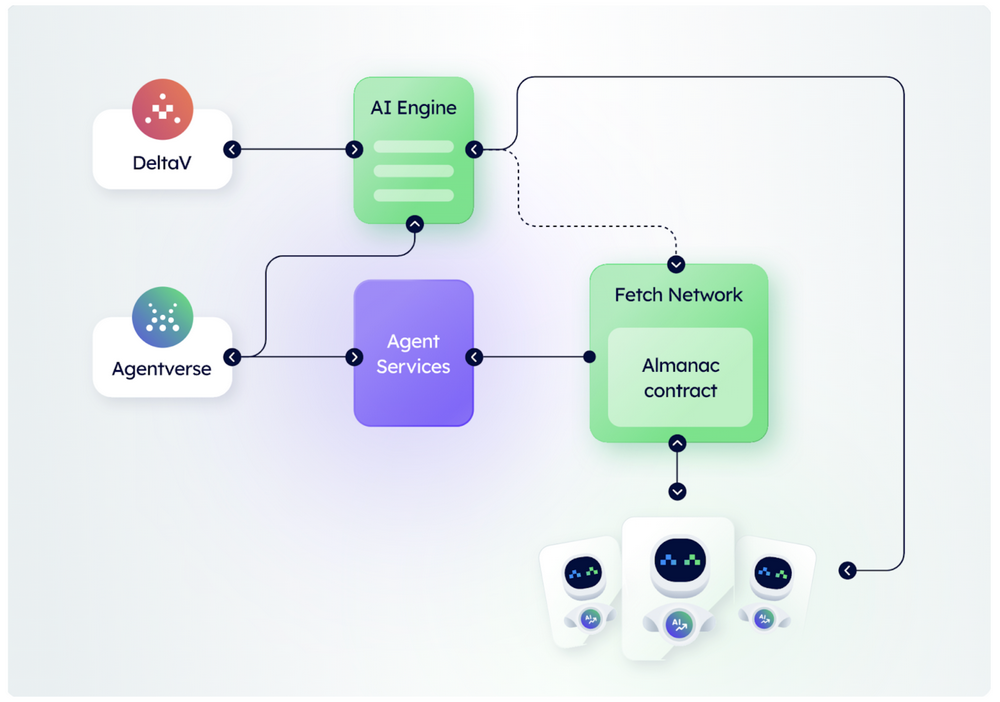
Fetch.AI 架构图,Source:Fetch.AI
上图是Fetch.AI的架构图,Fetch.AI对 AI Agent的定义式“一个在区块链网络上自我运行的程序,其可以连接、搜索和交易,也可以对其进行编程以便于其与网络中的其它代理进行交互”。DeltaV是创建Agent的平台,注册的Agent形成一个Agent库,叫做Agentverse。AI Engine是解析用户的文字以及目的,然后转化成代理能接受的精准指令,然后在Agentverse中找到执行这些指令的***适合的Agent。任何服务都能注册为代理,这样就会形成一个以意图为指导的嵌入式网络,这个网络能够非常适合嵌入到比如Telegram这样的应用,因为所有的入口都是Agentverse,并且在聊天框中输入任何操作或者想法,都会有对应的Agent在链上执行。而Agentverse可以通过来接广泛的dAPP来完成链上的应用交互任务。我们认为AI Agent有实际的意义,对于区块链行业也有其原生需求,大模型给予应用大脑,但是AI Agent给予了应用双手。
根据目前的市场数据来看,Fetch.AI目前上线的AI Agent大约有6103个,对于这个代理数量,在价格方面存在高估的可能性,因此市场对于其愿景 愿意给出更高的溢价。
參考來源
AI 公链
类似于Tensor、Allora、Hypertensor 、AgentLayer等公链,其就是专为AI模型或者代理所构建的自适应网络,这个是区块链原生的AI产业链一环。
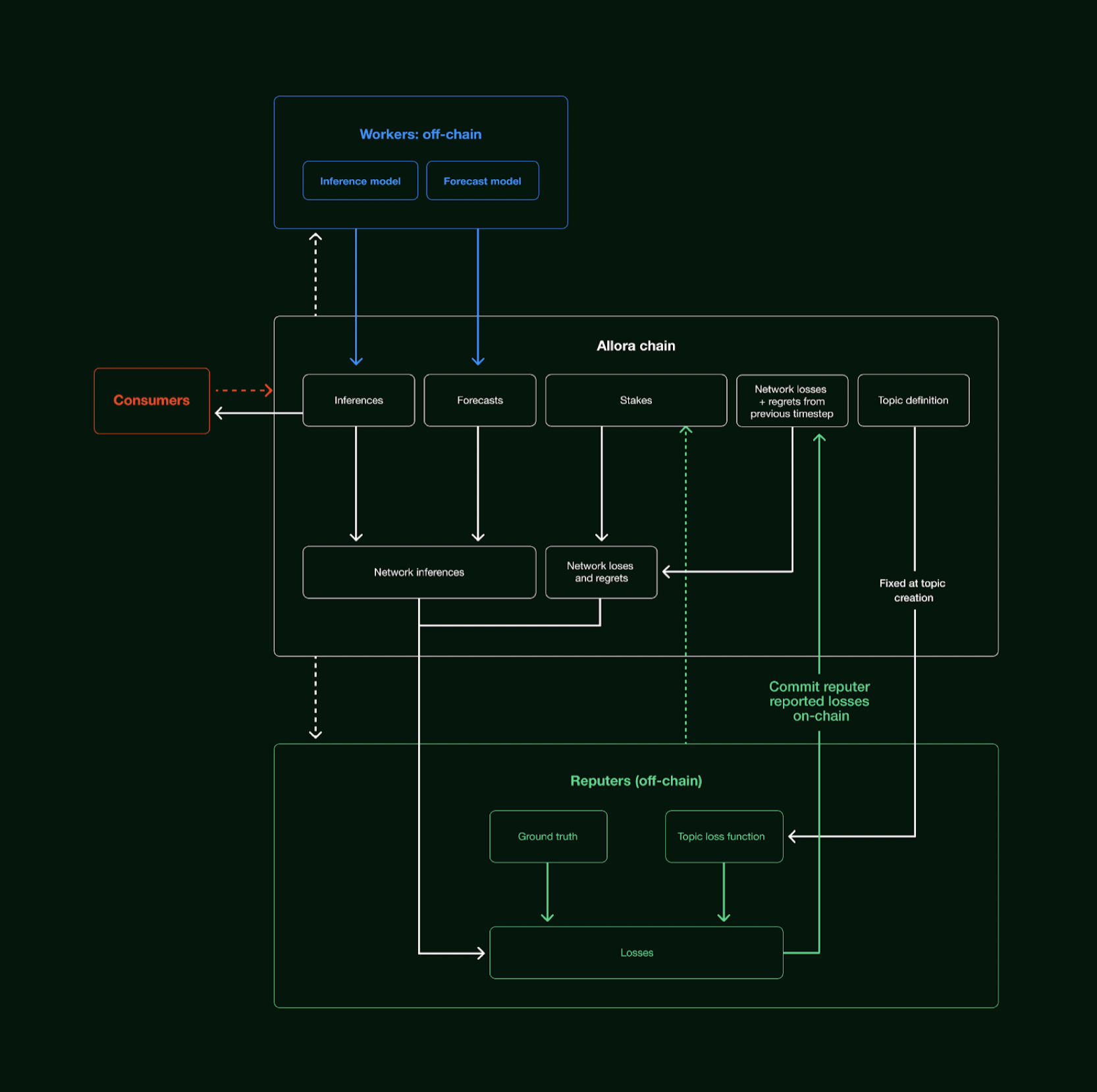
Allora架构,Source:Allora Network
我们以Allora来简述这类AI链的运行原理:
-
消费者向Allora Chain寻求推理。
-
矿工在链下运行 推理模型和预测模型。
-
评估者负责评估矿工提供的推理质量,评估者通常是权威领域的专家,以准确评估推理质量。
这种类似于RLHF(强化学习)将推理上传到链上,链上的评估者能够通过为结果进行排名进而改善模型的参数,这对于模型本身也是好处。同样的,基于代币经济学的项目,能够通过代币的分发显著降低推理的费用,这对项目的发展起到***关重要的作用。
与传统AI模型使用RLHF算法相比,一般是设置一个评分模型,但是这种评分模型仍然需要人工介入,并且其成本无法降低,参与方有限,相比之下Crypto能带来更多的参与方,进一步激起广泛的网络效应。
总结
首先需要强调的是,我们现在熟知的AI发展以及产业链的讨论实际上是基于深度学习技术,其并不代表所有的AI的发展方向,这里仍然有许多非深度学习并且有前景的技术在孕育,但是由于GPT的效果着实太好,导致市场大部分的目光都被这一有效的技术路径所吸引。
也有部分行业内的巨擘认为,当前的深度学习技术无法实现通用人工智能,因此可能这种技术栈走向的终局是死局,但是我们认为这一技术已经有其存在的意义,也有GPT这一实际需求的场景存在,因此就类似于tiktok的推荐算法一样,虽然这种机器学习无法实现人工智能,但是确实运用于各种信息流中,优化推荐流程。所以我们仍然认可这一领域是值得理智、大力深根的。
代币和区块链技术这种对价值重新定义与发现(全球流动性)的手段,对于AI行业也有其有利的一面。在AI行业中,发行代币能够让AI产业链中的各方面都进行价值的重塑,那么会激励更多人愿意在AI行业各个细分赛道深根,因为其带来的收益将变得更为显著,不仅仅是现金流决定其当前价值。其次,AI产业链中所有项目都将获得资本增值收益,并且这种代币能够反哺生态系统以及促进某种哲学思想的诞生。
区块链技术的不可篡改和无需信任的性质也有其AI行业的实际意义,能够实现一些需要信任的应用,比如我们的用户数据能够允许在某个模型之上,但是确保模型不知道具体的数据、确保模型不泄露数据、确保返回该模型推理的真实数据。当GPU不足够时,能够通过区块链网络分销,当GPU迭代,闲置的GPU能贡献算力到网络中,将废旧的东西重新利用起来,这是全球化的价值网络才能做到事情。
GPU计算机网络的劣势在于带宽,也就是对于HPC集群,带宽能够集中解决,进而加快训练的效率。对于GPU的共享平台,虽然可以调用闲置算力,并且降低成本(通过代币补贴),但是由于地理位置的问题,其训练速度会变得非常缓慢,因此这些闲置算力只适合于那些不紧急的小模型。并且这些平台也缺乏配套的***工具,因此中大型企业在当前状况下,更倾向于传统云企业平台。
总之,我们仍然认可AI X Crypto结合的实际效用,代币经济学能够重塑价值以及发现更广泛的价值视角,而去中心化账本能够解决信任问题,将价值流动起来,并且发现剩余价值。
参考资料
《Galaxy:全景解读 Crypto+AI 赛道》
《美股AI数据中心产业链全名单》
《You’re Out of Time to Wait and See on AI》
《GPT现状》
《AI INFRASTRUCTURE EXPLAINED》
WEEX唯客交易所是全球交易深度***好的合约交易所之一,位居CMC交易所流动性排名前五,订单厚度、价差领先同行,微秒级撮合,零滑点、零插针,***大程度降低交易成本及流动性风险,让用户面对极端行情也能丝滑成交。
WEEX交易所宣布将于今夏上线其全球生态激励通证WEEX Token(WXT)。WXT被设计为WEEX交易所生态系统的基石,作为动态激励机制,主要用于激励WEEX交易平台社区的合作伙伴、贡献者、先驱和活跃成员。
WXT总供应量100亿枚,初始流通量39亿枚,WEEX交易平台投资者保护基金、WXT生态基金各持有15%,15%用于持币激励,5%面向代理、渠道等合作伙伴私募,其余50%将全部用于WEEX交易所生态激励,包括:团队激励(20%)、活动拉新(15%)、品牌建设/KOL合作(15%)。WEEX Token是一种实用型代币,规划了丰富的使用场景和赋能机制,包括:Launchpad、近10项持有者专属权益,以及回购销毁通缩机制等。
据悉,WXT仅开放代理、渠道等合作伙伴折扣认购,未来零售投资者可通过新用户注册、交易挖矿、参与平台活动等方式获得WXT奖励。
点此注册 WEEX 账户,领取 1050 USDT 新用户奖励
WEEX官网:weex.com
WXT专区:weex.com/wxt
你也可以在 CMC|Coingecko|非小号|X (Twitter)|中文 X (Twitter)|Youtube|Facebook|Linkedin|微博 上关注我们,***时间获取更多投资资讯和空投福利。
在线咨询:
WEEX华语社群:https://t.me/weex_group
WEEX英文社群:https://t.me/Weex_Global








还没有评论,来说两句吧...